
Apache Spark is becoming the standard for a number of big data use-cases all around the world. Businesses all around the world are leveraging Apache Spark in their Big Data stack, courtesy of its advanced capabilities like in-memory computation, and this trend has catapulted the demand of individuals possessing skill-set in this domain.
This class, taught by a renowned Data Scientist working in the world’s largest consultancy firm, is intended as an introduction of Apache Spark. The class covers the following topics:
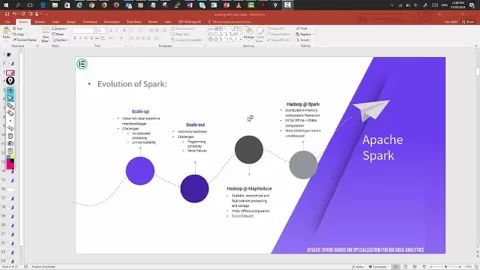
- History of Apache Spark
- Overview of Apache Spark unique and advanced capabilities
- Introduction of Apache Spark libraries (SparkSQL, SparkML, GraphX, Spark Streaming)
- How Apache Spark fits in Enterprises’ Big Data Architecture
- Understanding Apache Spark in the context of Hadoop Ecosystem
These concepts are crucial for developing strong foundation in Apache Spark. This class doesn’t require any prior programming experience and is well-suited for a broader audience including developers and business analysts who intend to get to know this amazing technology.







